
Context
In encoder-decoder transformer models, the decoder layer normally consists of a cross attention which performs key and value projections for encoder hidden states and calculate attention score between that and the query projection.
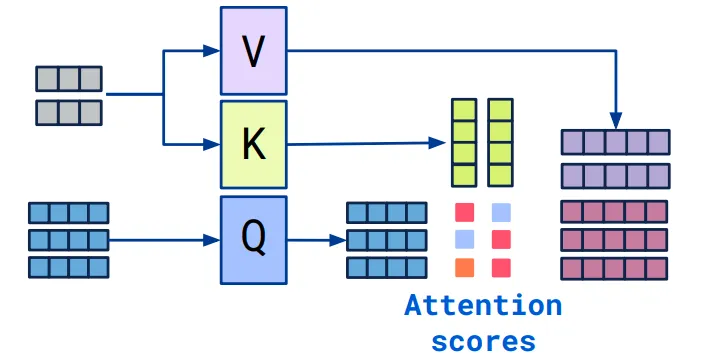
Notice that in common Seq2seq models such as Whisper, the encoder output that being fed into decoder never change in the autoregressive token generation loop, which means the key and value states can be saved after the first time we calculated them, and then be reused in the later decoder runs.
HF transformers repo implements this cross attention this way:
class WhisperAttention(nn.Module):
def forward(
self,
hidden_states: torch.Tensor,
key_value_states: Optional[torch.Tensor] = None,
past_key_values: Optional[Cache] = None,
...
):
# pseudo code
if past_key_values.is_updated():
k, v = use_cached_kv() # find cached kv from past_key_values
else:
k, v = compute_kv() # linear, transpose
k, v = past_key_values.update(k, v)
# calculate attention score using k, v
However in the torch.export, AOTInductor and ExecuTorch world, this code will be specialized to the else branch, since the past_key_values being used in export doesn’t have the KV states. The result is numerically correct, since we always compute KV projections but it’s inefficient, due to the fact that there’s no cache being used. We figured this encoder KV cache can play a big role in improving the performance.
Back of the envelope calculation
Let’s look at whisper-large-v3-turbo, this model has 4 layers of decoders, each consists of a self attention and a cross attention.
For each cross attention we are doing 2 KV projections (linear, view and transpose), both linear has input and output dimension 1280. The encoder output is of shape (1, 1500, 1280). ChatGPT tells me that’s roughly 9.8 GFLOPS (floating point operations) per token.
Solution space
If we have full control on the source code we can directly pass KV cache (precomputed KV projections) into cross attention like what whisper.cpp is doing. In one of the experiments of introducing MLX backend into ExecuTorch we also rewrote the model definition to take in precomputed KV projections directly.
However this requires drastic model definition rewrite, since we are changing the inputs to decoder and even adding another method. It’s also not easy to scale, for example in optimum-executorch, it’s almost impossible to rewrite all seq-2-seq models to make them exportable. This rewrite will have impact on the runtime as well.
The other way I decided to pursue is to make torch.cond work from export all the way to ET, in an efficient manner so that we can capture the perf gain brought by using KV cache, also providing a minimal building block which can be a drop-in replacement of the transformers model definition.
Make torch.cond work
We are not strangers to torch.cond and we wrote an exportable version of cross attention in torchtune so I was hoping this should be easy. We already know that torch.cond requires:
- Outputs of both branches have to have the same tensor metadata (dtype, shape, device etc)
- No aliasing or mutation allowed in any of the branches
My naive first version of torch.cond looks like this:
class WhisperAttention(nn.Module):
def forward(
self,
hidden_states: torch.Tensor,
key_value_states: Optional[torch.Tensor] = None,
past_key_values: Optional[Cache] = None,
...
):
def compute_kv():
... # k_proj, v_proj, view, transpose
return k, v
def use_cached_kv():
# doesn't support direct return, use clone() to avoid aliasing
return past_key_values.keys.clone(), past_key_values.values.clone()
k, v = torch.cond(past_key_values.is_updated(), use_cached_kv, compute_kv)
# need to write back the kv cache, move it out from torch.cond since no inplace mutation
k, v = past_key_values.update(k, v)
# calculate attention score using k, v
Notice that in this version, even for the “efficient” branch we still do 2 excessive copies. My hope was that this is an okay tradeoff, to save the calculation of the kv projections.
Custom ops
However when I lower whisper-large-v3-turbo to ExecuTorch, using AOTInductor CUDA backend, I observed the performance is even worse than before. I did some trace and it’s clear that we are adding 4 memory copies in each of the decoder run. Before torch.cond, we have 2 huge cudaMemcpys at the beginning and the end:
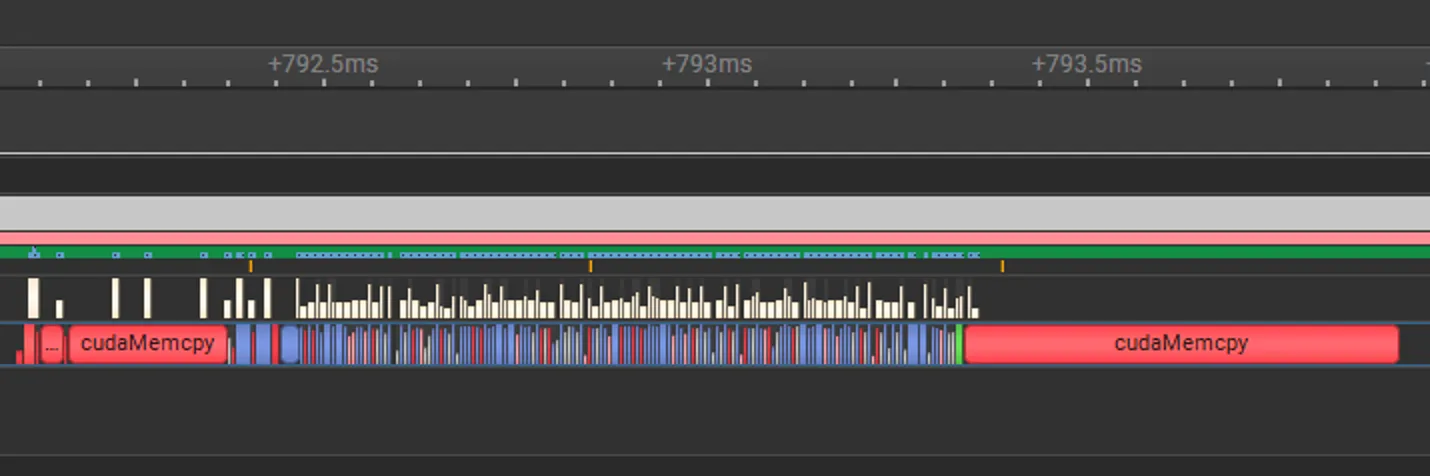
But after torch.cond, we have 4 extra copies in between:
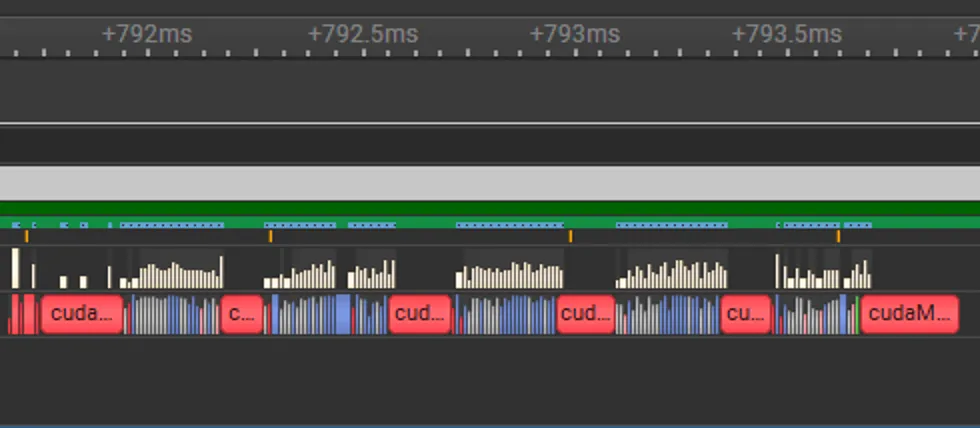
My takeaway for this version was that the clone is too expensive and we have to avoid it. After some head-scratching I remember custom ops can be used as escape-patch in a lot of the places in pytorch. So my next version looks like this:
class WhisperAttention(nn.Module):
def forward(
self,
hidden_states: torch.Tensor,
key_value_states: Optional[torch.Tensor] = None,
past_key_values: Optional[Cache] = None,
...
):
def compute_kv():
... # k_proj, v_proj, view, transpose
k, v = torch.ops.executorch.update_cache(past_key_values, k, v)
return k, v
def use_cached_kv():
# doesn't support direct return, use clone() to avoid aliasing
return torch.ops.executorch.alias(past_key_values.keys, past_key_values.values)
k, v = torch.cond(past_key_values.is_updated(), use_cached_kv, compute_kv)
# calculate attention score using k, v
I introduced 2 custom op, executorch::alias which does nothing but return the input tensors. executorch.update_cache takes in the KV cache and computed KV states, store the states into the cache.
These 2 ops are extremely easy to write and luckily I was able to come up with inductor lowerings as well. Using these 2 custom ops I can save the clone() in the previous version. Everything looks promising until…
Mixed Device Constants
Looking at the traces of using custom ops, things improved a bit but the 4 extra cudaMemcpy still exists, maybe just getting smaller.
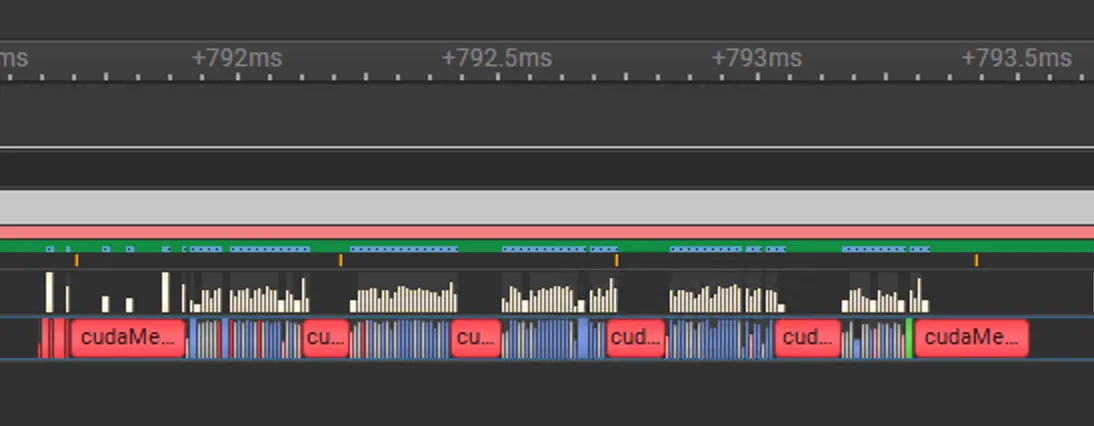
So apparently we are still doing some expensive copying somewhere. After a lot of debugging, I realized it was the predicate that requires a copy from GPU to CPU.
In my previous version I did something like:
cache_is_initialized = (past_key_values.keys != 0).any() k, v = torch.cond(cache_is_initialized, use_cached_kv, compute_kv)
In AOTInductor generated wrapper code it becomes:
bool buf2_scalar;
AOTI_TORCH_ERROR_CODE_CHECK(aoti_torch_item_bool(buf2, &buf2_scalar));
if (buf2_scalar) {
In order to get the boolean value, aoti_torch_item_bool has to do a cudaMemcpy to copy buf2 to CPU memory. Even though it’s just 1 boolean element, it’s still expensive!
So my next version will have to avoid expensive cudaMemcpy. We can have a flag in CPU memory and flip it to true after torch.cond returns. This way, the next time we look at the same flag, we can go with the use_cached_kv path. This means AOTInductor needs to support mixed device buffers/constants, the predicate buffer is on CPU and all the other buffers are on GPU.
My final version:
class WhisperAttention(nn.Module):
def __init__(
self,
...
):
self.register_buffer("cache_initialized", torch.zeros(1, 1, dtype=torch.bool, device="cpu"))
def forward(
self,
hidden_states: torch.Tensor,
key_value_states: Optional[torch.Tensor] = None,
past_key_values: Optional[Cache] = None,
...
):
def compute_kv():
... # k_proj, v_proj, view, transpose
k, v = torch.ops.executorch.update_cache(past_key_values, k, v)
return k, v
def use_cached_kv():
# doesn't support direct return, use clone() to avoid aliasing
return torch.ops.executorch.alias(past_key_values.keys, past_key_values.values)
k, v = torch.cond(self.cache_initialized, use_cached_kv, compute_kv)
# flip the flag
self.cache_initialized.fill_(True)
# calculate attention score using k, v
Apparently I’m the first one doing this on AOTInductor so there are some rough edges to work through. After working with AOTInductor for several days (issues: #168398, #169118, #169197 and PR #169504) This works perfectly:

Not only we got rid of the extra copies but we also bumped decoder token/s from 515 to 640!
Conclusion
I think this solution is generic enough to be able to support all of the cross attention implementations in transformers repo. There are some other performance levers that we can pull (look at those 2 huge cudaMemcpys at the beginning and the end of the trace).
I also hope this note can give people new to this field some hints on how important it is to avoid expensive copies (Amdahl’s law). Feel free to comment and share your thoughts on this!
